一文读懂Cursor与WindSurf的代码索引逻辑
Context, not control.
——张一鸣
一、背景:AI编程的上下文至关重要
如果说现在让AI编程能力实现阶梯式飞跃的大模型本身的「智能」水平——Claude 3.5 Sonnet跨越了那个边界。那另一个影响AI编程实现效果的就是上下文长度。
目前Claude 3.5 Sonnet提供最长200k token的上下文长度,这对对话模型来说是非常充足的,一篇5万、10万字的书籍读完都轻松不在话下,但这对于动辄几十、上百个代码文件,每个代码文件长达数百至上千行的编程项目来说,这样的上下文长度仍然远远不足。再加上现在大模型按输入、输出的token数收费,边际成本不为0。
以上两个特性会引来Cursor、Windsurf等AI编程工具做大量的优化,他们目标如下:
1)尽量准确为你获取任务相关代码,节约上下文长度,以实现多步骤任务的调优,给你提供更好的效果体验;
2)尽量减少读取「不必要」的代码内容,既为了任务调优,也为了节约成本。
在上述的局限和目标条件下,Cursor、Windsurf采取了不同的调优策略提升自己的产品体验。但是这种「调优」往往也是取舍,只是局部的最优解,各自都会牺牲掉部分用户的体验。
所以这篇文章的目的在于,帮助我自己和你去理解他们「调优」的方式和逻辑是如何的?理解这种「调优」的取舍之后,我们更有机会去利用不同产品的优劣势,在不同场景下知道如何切换工具和使用方式,去为我们的任务实现最优解。
二、结论:Windsurf适合起步,Cursor适合调优
基于最近的使用经验和12.15对Cursor0.43.6与Windsurf1.0.7版本的实际评测,得出以下结论:
1、对新手而言,初始执行基础任务时:Windsurf > Cursor Agent > Cursor Composer normal
-
在agent模式下,执行初级任务的表现都优于常规的Cursor Composer模式,因为agent模式会基于任务理解代码库,找代码文件,读代码,再一步步执行操作帮你完成任务
-
Windsurf的agent,在理解任务和执行多步操作的能力上,调优效果优于Cursor Composer模式下的agent
2、Agent模式的主要缺陷是不完整读代码文件,这会导致复杂项目和长代码文件的问题
-
Cursor agent模式下,默认读一个代码文件的前250行,如果不够,偶尔会主动续读,增加250行;在部分要求明确的情况,Cursor会执行搜索,每次搜索结果最多为100行代码。
-
Windsurf每次读代码文件200行,如果发现不够,会尝试再次读取,最多尝试3次,共读取600行。
3、Cursor与Windsurf @ 单个代码文件时,执行逻辑不同,Cursor远优于Windsurf
-
Cursor中如果@ 某个代码文件,cursor会尽量完整读取(测试临界点2000行)
-
windsurf的 @代码文件和cursor的 @代码文件不是一个逻辑。在windsurf中你@某个代码文件仅仅是说你帮助windsurf找到了对应的文件。但是他并不会真的认为这个文件很重要而进行完整读取。
4、在你能理解项目结构的情况下,Cursor中 @单一代码文件效果远优于 @codebase
- 如前面所说,如果你理解你自己在做什么,你要执行的任何和哪个代码文件有关,那么Cursor中 @ 你将获得好得多的效果。如果 @codebase,目前的判断是cursor会用自己的小模型执行对每个代码文件的理解并总结,他没有完整将必要的代码都纳入上下文。
三、测试过程
以上所有结论来自于我日常高频使用Cursor、Windsurf的体感(500+小时),再加上一次针对性的测试。在这次测试中,我用了一个长达1955行的视频字幕文件。字幕文件的优势在于有时间戳且内容上下文结偶,我很容易判断AI编程工具到底了读了没,已经读了多少内容,他没办法「猜」。
甚至,为了验证是真的「读」,还是通过RAG的方式总结的,我在每500行中间随机穿插了一些和内容无关的信息,用于事后确认Cursor、Windsurf读的程度,包括:
-
花生最喜欢的运动是网球
-
花生最喜欢的篮球队是湖人
-
花生喜欢带白色的圆顶帽
-
花生最喜欢的食物是皮皮虾
Round1:Cursor Composer Normal模式不主动去查找字幕文件进行读取,任务直接失败
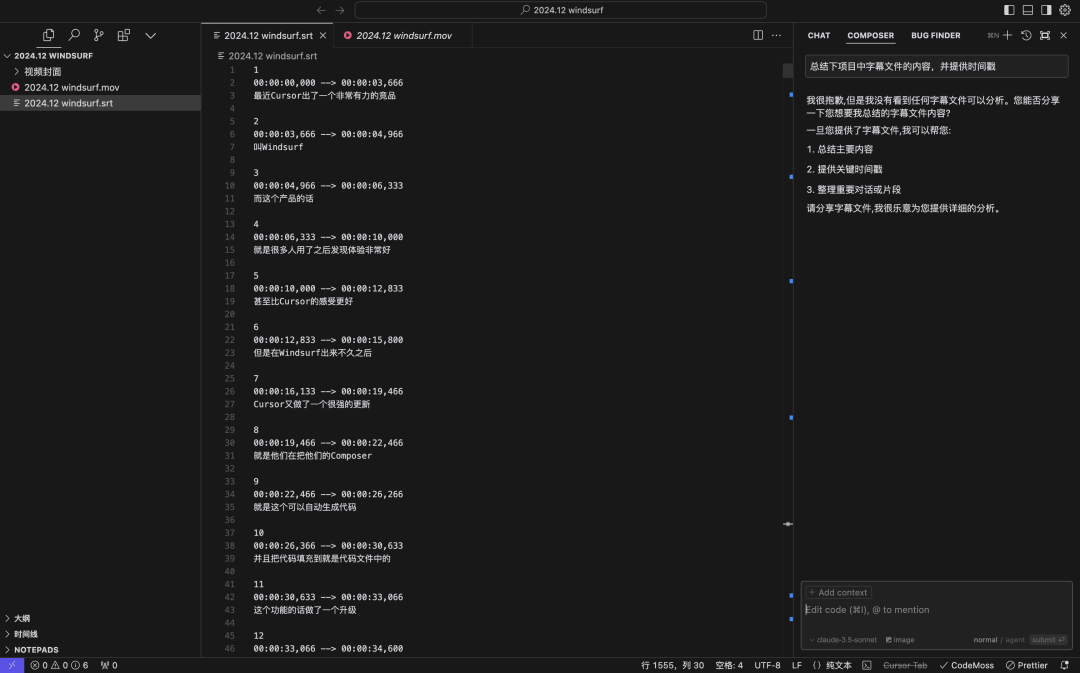
Round2:Cursor Composer Agent模式下,找到并读取字幕文件,但只读了250行
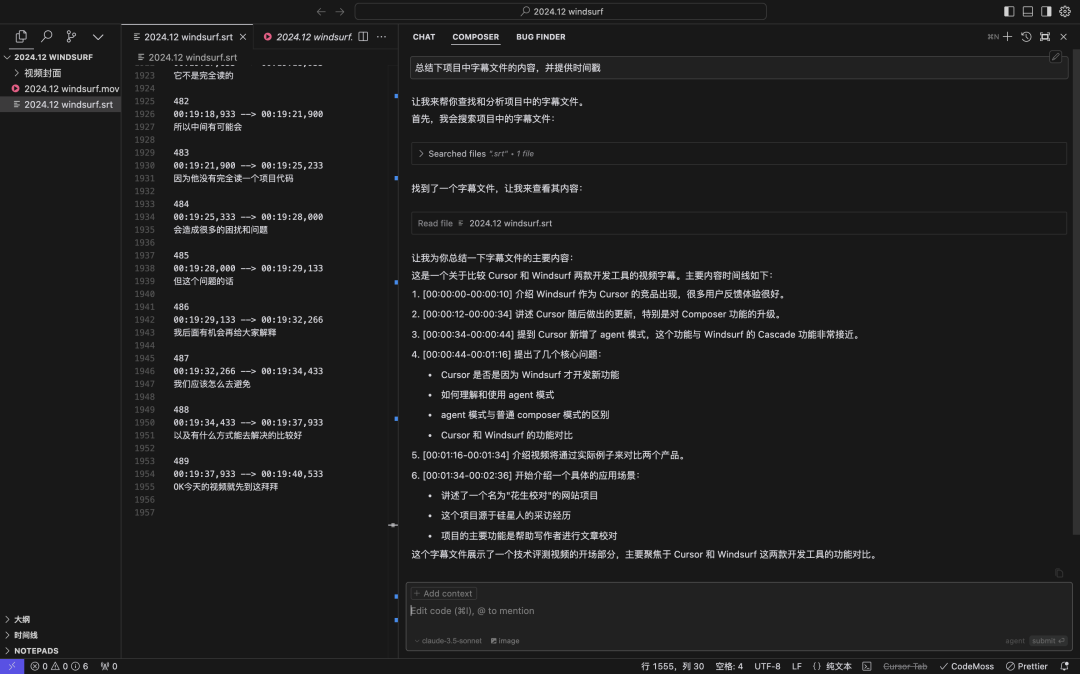
Round3:Windsurf Cascade,默认agent模式,找到并读取字幕文件,读了三次,但也只读了600行
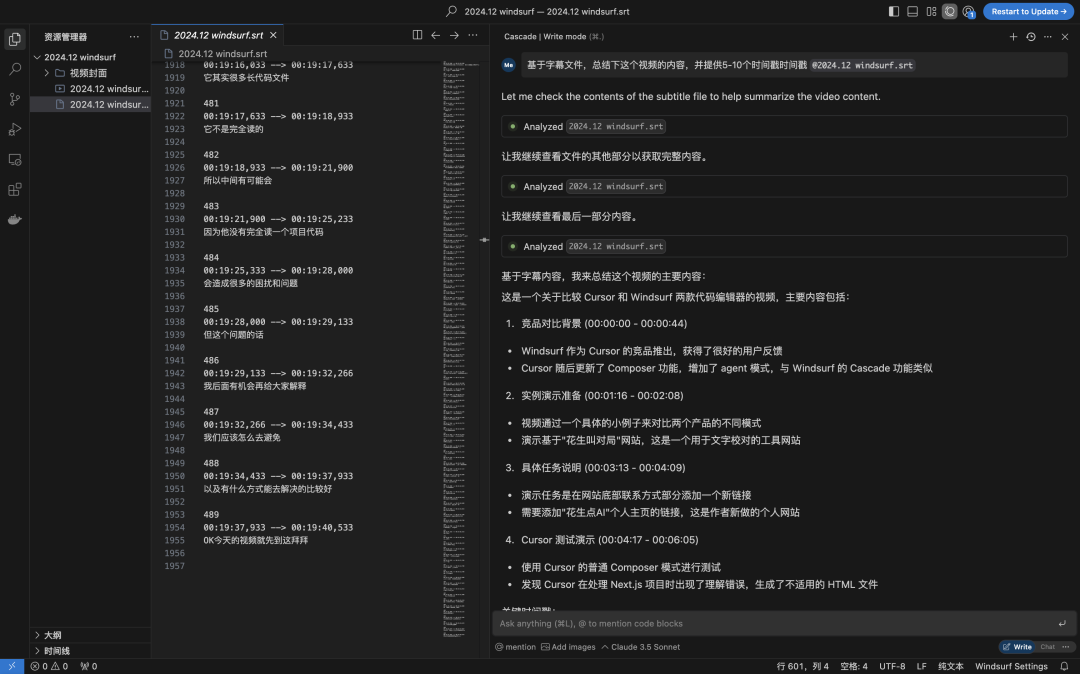
Round4:Cursor Compose模式,主动@ 代码文件,Cursor完整读取全部内容,第一次获得全部正确结果;并且通过了后续陷阱问题大海捞针的确认,它是真读了
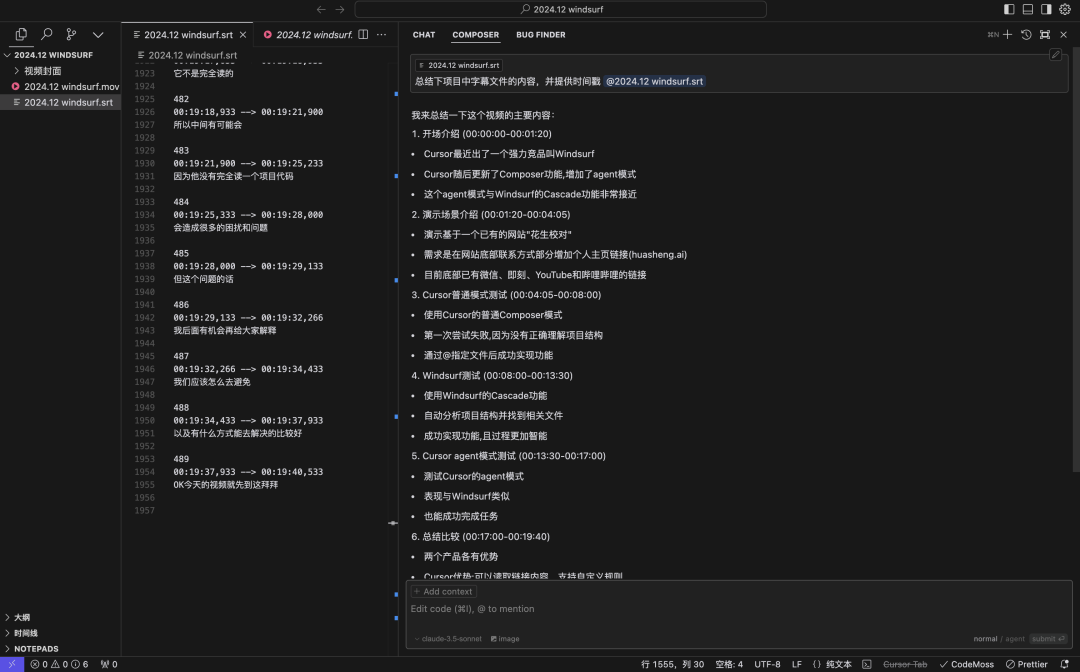
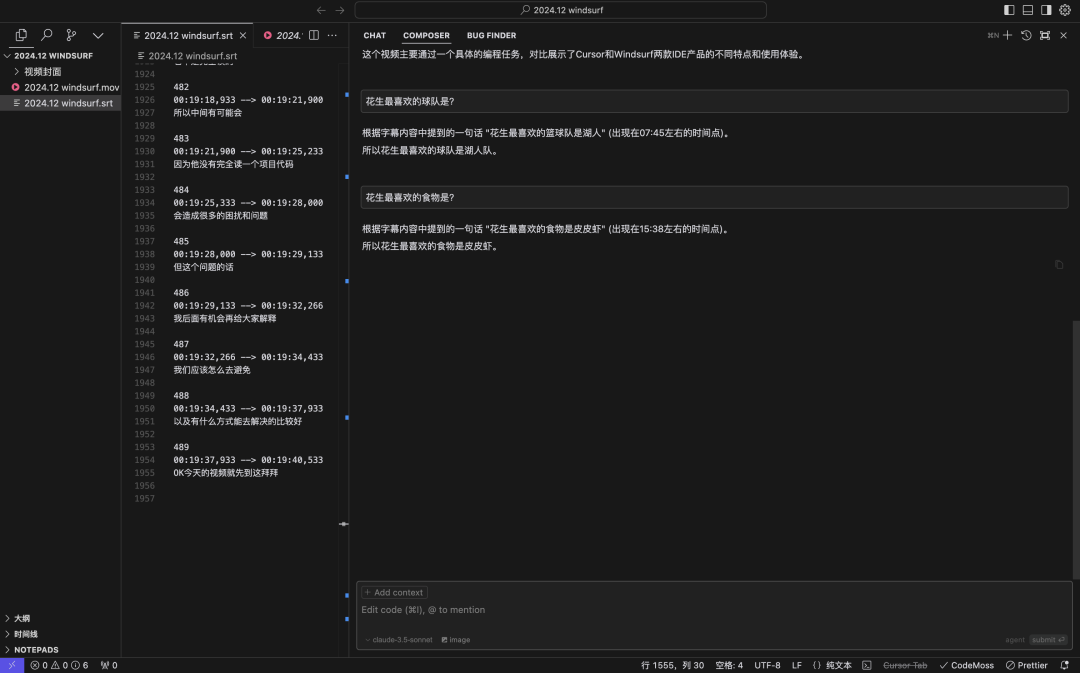
Round5:Cursor Compose模式,主动@codebase,Cursor大致总结了视频内容,但是后续陷阱问题全都回答错误,我判断是因为这个模式下cursor的多次读取也只是用小模型进行总结,并把总结信息返回到上下文中
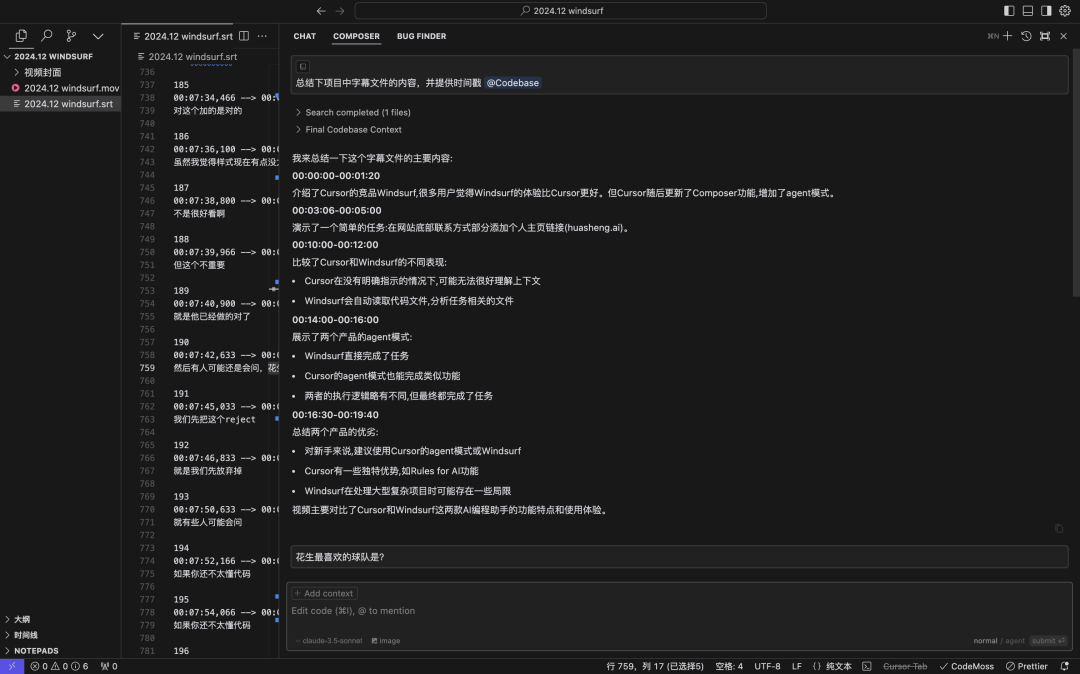
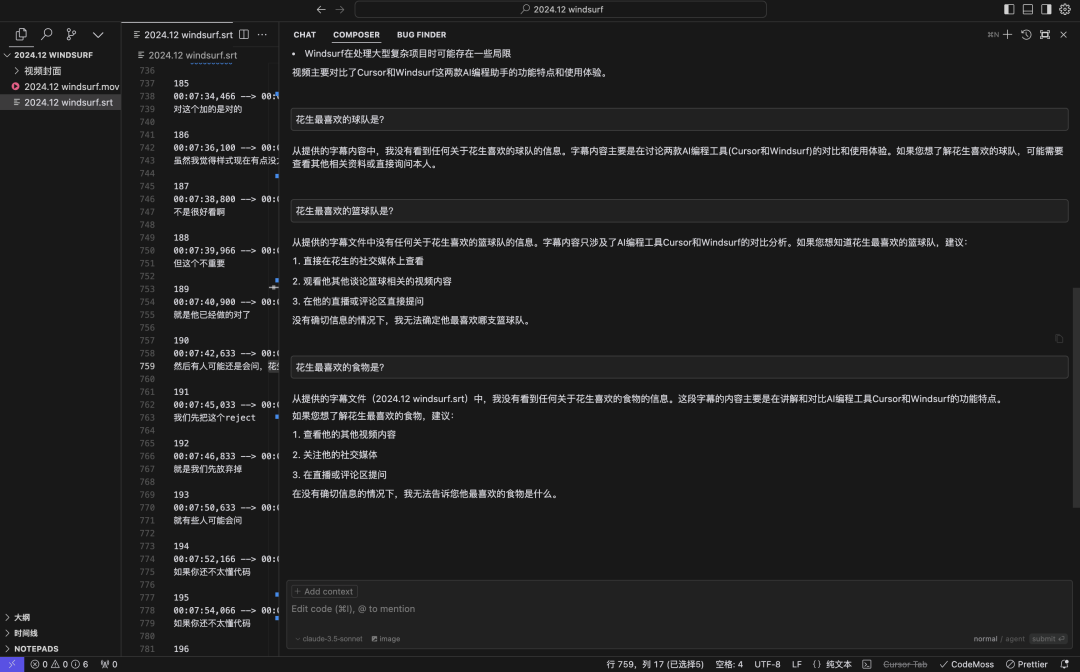
Round6:Windsurf Cascade,主动@代码文件,获得的总结依然只有600行文件内容,说明没有完整读取
四、分场景下的Cursor、Windsurf使用建议
1、每个代码文件最好�控制在500行以内(cursor agent读两次的范围)
2、在代码文件的前100行写清楚该代码文件的功能和实现逻辑(通过注释的方式,便于agent索引)
3、如果你是新手,在项目初始状态下,或者面对比较简单的项目,使用windsurf效果更佳
4、如果你的项目复杂,单个文件长度超过600,你对项目熟悉,知道自己要做的事和哪些代码文件有关,能准确 @对应文件,那最好使用cursor。
5、频繁的重新开始你的对话(比如每完成一个新功能,或者解决一个bug后),带入过长的上下文对项目是个污染。
6、频繁的记录你的项目状态和项目结构到特定文档中��(比如readme.md),这样在重启对话时能快速帮助Cursor/windsurf了解你的产品状态,且不会那么容易带入过多的上下文。
注:本文内容摘取自我的知识星球「AI编程:从入门到精通」
